I recently proposed that an email address be simplified in order to improve the user experience, and I used mathematics to justify the idea. I proposed to replace the email address it-support-xyz-na@company.com with help@company.com. Ignoring the common ending, the chance of randomly discovering the first email address is 1 in 1,133,827,315,385,150,000,000,000 (2617 or 1.13 septillion), which means that you have a better chance of winning the super-lotto multiple times. With those odds it would make a better password than it does a customer service email address. The chance of randomly discovering the email address that I suggested is 1 in 456,976 (264), which seems much more sane.
As I thought about the problem it occurred to me that the chances of randomly discovering the email address that I suggested is probably better than stated above since it is a word that English speaking people already know (and readily associate with what they are looking). As far as I can tell there are less than 250,000 words in the English language, which nearly doubles the chances of discovering help@company.com. This idea made me think about string guessing algorithms and the assumptions that are made when evaluating them, specifically algorithms designed to guess passwords.
Before we can get into any details we must first understand how a miscreant may try to crack a password. Passwords are normally hashed using a one-way algorithm prior to being stored, which means that the only way to check if a given string matches the strored password is to run the hash on the supplied string. So, in order to guess a password, an algorithm has to be designed which iterates over a set of possible solutions using the same one-way hash and compares the result to the hashed password.
Empirical analysis can be performed on any one-way hash algorithm to determine how much time it takes on average to perform the hashing operation. Given this information we can determine how many passwords can be checked in a given time period. Lets assume that the algorithm we are working with can compute 1000 hashes per second (60,000/minute or 3,600,000/hour or 86,400,000/day) on our private beowulf cluster.
Using this information we can examine the assumed effectiveness of standard password policies. Most strict password policies require choosing a password with at least one lower-case letter, one upper-case letter, and one number or symbol. So, for each position in the password there are 92 possible characters (26 lower-case characters + 26 upper-case characters + 10 numbers + 30 special characters). If the policy requires that the password be at least 8 characters long, then the number of possibilities is 5,132,188,731,375,616 (928). That means it would take 162,740 years to try every combination, but probably only 81,370 years to find the correct one (which is still much less time than for the IT support email I mentioned in the beginning of the article).
So far it seems that the standard password policy is extremely effective; a password selected under this policy should be fairly secure even if computing efficiency is increased by orders of magnitude. Of course, in order for this to be true the end users would have to pick passwords which are as close to random as possible, and that is where this idea of security begins to unravel. My thesis is that when password stringency requirements are increased users find it more difficult to remember their passwords and thus resort to using shortcuts which help them remember their password. The use of these shortcuts dramatically decrease the effectiveness of the average password yet the IT department thinks that they are forcing people to use secure passwords.
Based upon my experiences working in an IT department for a major multi-national company, I think that faced with strict password policies users often pick one or two words which they can remember and then add on the numbers or special characters which are required. For example, users will take their selected word, capitalize it and add a number or special character to the beginning or end (“2FurryCats” or “SmellyCat$”). Or, they will pick two words they can remember and join them with a number or special character (“Love4Kittens”).

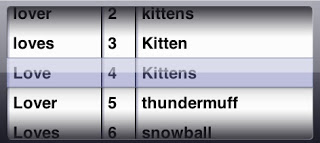
Since “Love4Kittens” is 12 characters long it would theoretically take longer to randomly discover than the 8 character long password we just discussed. However, if we knew that this user actually loved kittens, we could modify our algorithm to account for this. Instead of each column testing just one character at a time we could modify it to also test certain key words or phrases.
 </a>
</a>Assuming that we can guess what the user’s interests are we can drastically reduce the amount of time required to discover a person’s password using the brute force techniques. If we take the original 92 characters and add 158 key words for this person then each column contains 250 possible choices, so it would take at most 15,625,000 (2503) guesses to figure out this password. Using our assumptions above, this would take less than 5 hours to guess. That may still sound like a lot of computing time, but it is a remarkable improvement over 162,740 years. This theoretical algorithm could be started before you go to bed, and when you wake up it would have a password for you (assuming that you knew the user well enough to correctly guess their interests).
I have evaluated my important passwords against this technique, and fortunately they are still fairly safe. The passwords that I have which are weakest against this sort of technique are the ones that I am required to change every 3 to 6 months. It is hard to keep coming up with good passwords that are memorable, so I, like most people, just take shortcuts. I have started using pseudo-random passwords for accounts which I can access from my personal devices, but I use 1Password to keep track of these. And, when I design corporate software I do my best to use single-sign-on concepts to help minimize the number of passwords my users are forced to remember. I am sure that I am not the first person to think of this technique, so it would be wise to use this method to evaluate your own passwords.
Note: Notice that I wrote most of these numbers out even though they are ridiculously large; that is not because I do not know how scientific notation works, it is because my audience may not appreciate how scientific notation works. I think that when a person with a limited mathematical background looks at numbers in scientific notation they underestimate the number because of its abbreviated form.


