Recent break throughs in neural networks have made the use of computer vision technologies available to a wider audience, and many businesses are looking for ways to apply those technologies. To address the demand, large cloud service providers now providing basic turn-key computer vision services. Computer vision solutions currently perform best when they are asked to do tasks which are limited in scope. So, unless pre-trained models are already available for the task at hand, there could be a steep cost to implementing computer vision.
To make things worse, there are relatively few people who understand computer vision technologies from a wholistic perspective. This dearth of experience is not due to lack of educational resources, rather it is due to the steep learning curve and the inverse distribution of educational materials. There are many ways to learn how to get started with a computer vision project, but there are fewer resources explaining how to apply those initial learnings to harder real world problems.
Due to those challenges, it can be hard for technology managers get the information they need to make informed decision about the implementation of computer vision systems. In this post I will discuss ways to avoid some of the common problems encountered when non-tech companies attempt to implement custom computer vision solutions.
In graduate school I studied the books Concise Computer Vision by Reinhard Klette and Computer Vision: Models, Learning, and Inference by Simon J.D. Prince. These books, and others like them, gave me confidence in understanding the fundamentals of computer vision, but they lacked information on how I could apply those technologies. To make things worse, since those books were written the field has moved to almost exclusively using neural networks. Deep convolutional neural networks use the basic principals described in the academic sources, but they are somewhat obscured by the focus on neural network architecture.
In addition to technical challenges there are challenges related to understanding applicability of the technology and the engineering work required for its application. I failed to appreciate these exact things when, full of confidence from my technical education, I ran into my first computer vision project and was knocked on my ass. By the time I had finished the third computer vision project I was starting to see some common pitfalls. But, rather than focusing on the pitfalls, I prefer to focus on how they can be mitigated. So, below are some topics you should be thinking about before entering into a computer vision project.
But, before we dive in, let’s cover some basic terminology. Each of the real world items that will be learned by the computer vision process are called classes. If the goal is to create something which can distinguish squirrels from birds, then there would be two classes, squirrels and birds. The knowledge which is gained from training things for computer vision is stored in a bundle of files known called a model.
Many technical managers and implementers are tempted to skip over this step. The reason that they are even considering using computer vision is because they understand the problem domain and how it would benefit from computer vision. Unfortunately, just because a problem could benefit from computer vision, it doesn’t mean the problem lends itself to being solved by computer vision solutions. This mismatch can manifest in many ways, but normally it is related to the physical items being indistinguishable from each other in various ways.
The first time I encountered the problem of indistinguishable computer vision classes was on my second project. The goal of the project was to create a proof-of-concept inventory monitoring system. We worked with the client to get a random sampling of the inventory so that we could create a prototype computer vision model to validate viability. Based upon success of the early prototype the client was encouraged to move forward with a second prototype that covered a larger sampling of the possible classes. When we received the additional items we quickly found a problem.
The items which we were supposed to detect were all cubes with the distinguishable part on the top face. However, in the expanded batch we found that the top faces of many of the cubes were identical. After speaking with the customer we discovered that the items were completely identical except for a single label on a single face of the cube. This meant that for certain subset of the problem there could be at most a 25% chance that we could detect them from one another. We proposed grouping all the indistinguishable classes and then using secondary sources to infer the actual breakdown of the group, but the project was ultimately shelved while other approaches were tested.
Having learned from that experience we were more explicit with customers about what constitutes inter-class similarity. But, later we experienced another variation on the same problem. In this new case the items were all visually different on the face which was to be detected. The problem was that when the items were in their target environment the distinguishable portions of them were partially to nearly completely covered. Not being able to see the part of the items that set them apart from others in their class was only half the problem. The items were covered in ways which caused different classes to be detected as the same because of similarities in the covering.
Another problem we experienced related to class differentiation was when a classes had a lot of variability but few examples of each of the various versions. In one specific example we had a hundred example images for an item, but there were almost twenty variations which had significant visual differences. The net effect was that we were left with twenty sub-classes that only had five examples per class.
The final problem we have seem is skewed class distributions. When we train computer vision models we take explicit steps to minimize class skew, but when there is a heavy-tailed distribution, even those techniques can’t unskew the data. In one case we had the number of examples in the tail was over twice the examples in the body of the distribution. Without strategies to increase the number of examples for each of the underrepresented classes in the tail we have to resort to clipping the examples in the body of the distribution. If, after clipping, the average number of examples per class is still below the per-class minimum, then a valid model cannot be created.
Once you thoroughly think through the target domain and are confident that it is in fact a good candidate for a computer vision solution, you need to understand the processes which are required to gather all the needed data. Images are obviously required to train computer vision systems, but for object detection tasks an annotation step is also required. There are few different types of computer vision tasks, two of the most common are image classification and object detection. Image classification is when images are tagged with certain labels, a now classic example of this is not hotdog. Object detection is used when specific parts of an image need to be detected. If we had an image of puppies and wanted to know how many puppies are in the image then we would use object detection.
All computer vision models need to be trained, which means training examples must be provided. For custom applications you have to provide all of those examples. While image classification just requires associating images with tags, object detection requires that the training images be annotated. In this context annotation is the process of looking at all of the training images and manually marking the items of interest in the image. For the puppy counting example we would need a lot of pictures of puppies, and we would need to open each of those images and draw a box around the puppies in them. Doing this correctly can take a lot of time.
Once properly annotated images are available, the model can be trained. Training a computer vision model from scratch can take weeks. Fortunately, we normally don’t train models from scratch. The common practice is to pick a model that is already trained and retrain it to learn a new domain. Retraining has downsides, but that is beyond the scope of this article. Even retraining can take days. There are strategies to reduce training time, but for most cases it safe to assume that creating or updating a model will take a significant amount of time.
A trained computer vision model can served up for use on API servers or directly on consumer devices. The run-time characteristics of a model is determined by its architecture. There are some computer vision model architectures, such as SSD Mobilenet, which can run in near real-time on consumer devices. But, like all things related to computer science, there are trade-offs. The faster models are generally less accurate, and the more accurate models require more memory, more time, or more compute resources to run.
To train an effective computer vision model you will probably need more data than you originally think. There is a rule of thumb that says at least fifty annotations per class is needed, but in practice more could be required. In our experience, when the visual difference between classes is subtle or multiple distinct views of an item are required, then more images will be required. If there are a lot of classes and a lot of images of each is required, then strategies will be needed to capture all of that information. And, each of those images will require classification or annotation.
The math to estimate how many total training examples you need is simply, but it is multiplicative. If we assume that there is one class per image, you have 250 classes, and you need at least 50 images per class, then you will need at least 12,500 training images. A lot of people tens to see what seems to be relatively small numbers and underestimate what is required. Because those two numbers need to be multiplied, the requirements explode quickly.
The accuracy of a computer vision model can be deceiving. First, which metric is being used to derive the quoted number? Is it precision? Recall? Mean average precision Or perhaps the f-score? Even if we assume that it is the mean average precision (mAP), which is commonly used in computer vision, what does the underlying distribution look like? Because it is an average, some classes will score above that number and some below. It is key to understand the per-class accuracy. If there are some classes which are more important, or more relevant than others, then you want to make sure that those classes are not at the low end of the accuracy distribution. Historically, per class metrics has not worked out of the box for Tensorflow, so it takes work to make sure these values are recorded. If the computer vision specialist cannot provide detailed per-class statistics, then they may be flying blind, and it could be a sign of problems to come.
There are three kinds of lies: lies, damned lies, and statistics.
– Mark Twain (Samuel Clemens)
There are more pernicious ways in which accuracy values can be deceiving. An example of this is overfitting. Overfitting is when a computer vision model basically memorizes the images it was given for training. The model doesn’t have a generalized understanding of the classes, rather it just learns to identify all examples of those classes which were found in the training set. Models that are overfit fail spectacularly when deployed in the real world. As an example, if someone was training a food recognition model and they only gathered training images by standing in front of their refrigerator, their trained model may work amazingly well when test it on their own refrigerator. However, that exact same model would likely not work at detecting food in any other refrigerator.
Overfitting is more likely to occur when training is improperly set up, but it can happen with proper configurations as well. It has been my experience that overfitting is a common problem, across domains, when working with neural network models. It may have different root causes or go by other names, when creating generative adversarial networks (GANs) the phenomenon is called mode collapse, by the end result is the same. The model learns some aspects of the specific things it was presented in training and has no general concept of those things.
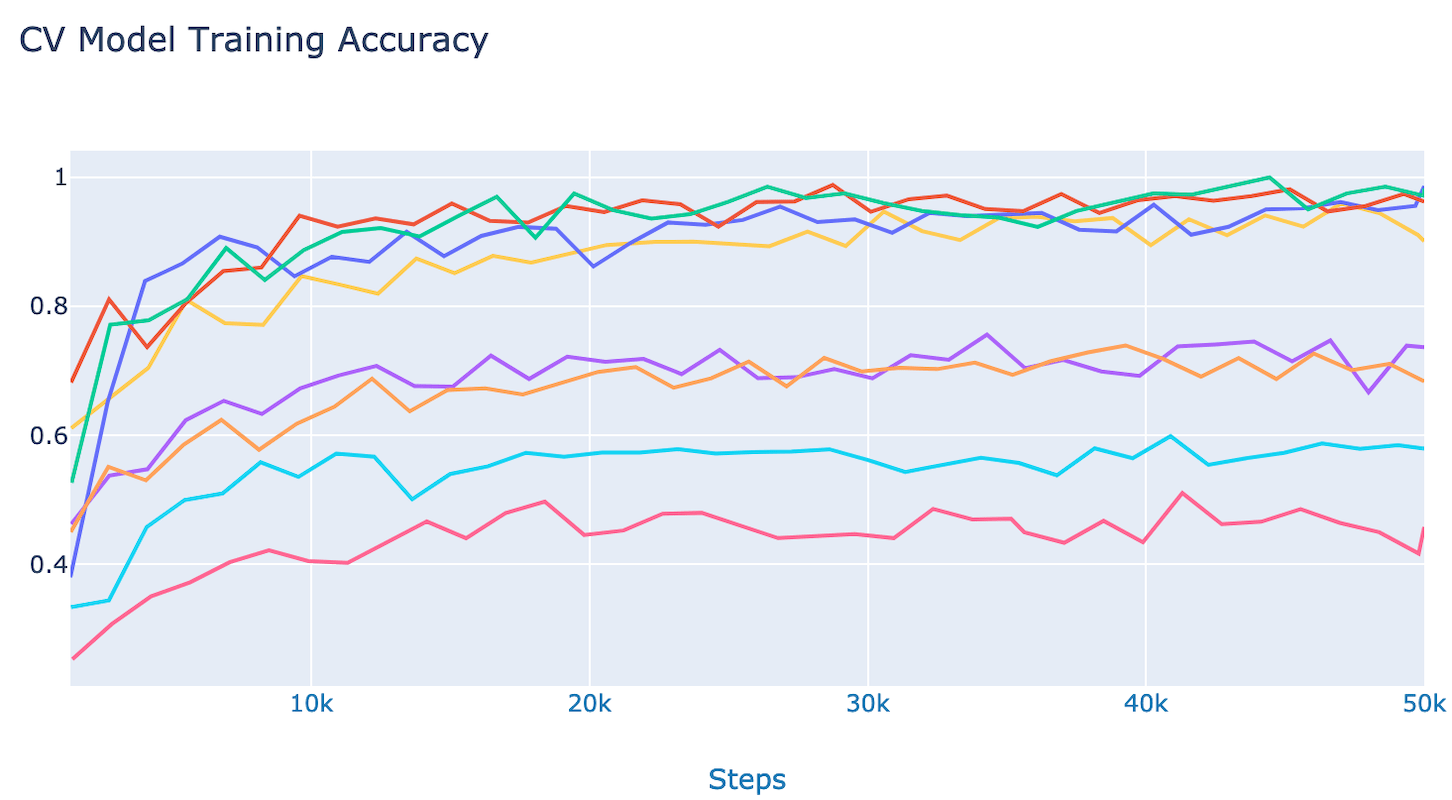
The chart above illustrates how deceptive performance metrics can be. The data in the chart represents the accuracy of eight different computer vision models as they were trained; training step number is on the bottom and expected accuracy is to the left. Four datasets were trained using two different techniques. The clustering of lines at the top were trained and validated with the same set of data, meaning the exact same set of images which were used to train the model were also used to validate the model. The lower four lines were trained and validated with segregated datasets. So, the lines on the top represent how effectively the model could memorize the images it was shown, while the lines on the bottom give a more realistic estimation of how the models would perform on new data.
My rule of thumb is that if I am seeing precision or recall values above 0.8 in the early stages of a computer vision project, then I get concerned about overfitting. This is a very rough rule of thumb which varies depending upon which network architecture is being used, but the take away is that if the early results seem too good to be true, they probably are. I have seen cases where high early accuracy results were used to justify the funding of computer vision projects. Then, after investing a lot of money in the project they struggle to get performance anywhere near what they saw in the prototype. We have been called to help save projects in this state, but when the answer is that it will take a lot more data collection and annotation the projects normally get canceled.
Considering the troubles described in the first four factors it may be easy to conclude that the only surefire way to implement a computer vision product is to follow a waterfall paradigm. First, get all the needed data, train a mode, write software, then achieve amazing success. But, just as waterfall software development projects are more likely to fail (except in highly regulated situations), our experience has been that taking a waterfall approach with computer vision projects is also more likely to fail. Truthfully, we have found that to be true for all big data projects. Computer vision products should be agile. The failure of a computer vision system should not be a blocker, it should be an inconvenience.
Success requires an adjustment of expectations. People tend to jump from computer vision all the way to complete automation, but based upon what we have discussed, complete automation may not actually be possible. And that doesn’t have to be a bad thing. Many times even partial automation can have profound impacts. It is much better to go into a computer vision project from the perspective of eliminating menial tasks and enabling human creativity. When problems are thought of in these terms, solutions are built to augment human capabilities rather than replace human capabilities. That means the systems are designed to have a human in the loop, and that human can handle exceptions and help train through new scenarios.
One of the core concepts of agile software development is to continuously deliver software that is incrementally better with each iteration. Great software teams do this because they are aware of their limitations. Software is built to enable domain experts to accomplish their jobs more efficiently, and it is rare that the best software engineer for a given task is also the domain expert. So, the software team builds software to the best of their ability and current knowledge, and they wait for feedback from the domain experts on how the solution could be improved. This same technique should apply to computer vision products as well.
Computer vision models should be provided early, even though they are incomplete. The key is that the software around the computer vision model should be designed in such a way that its users can provide feedback which flows all the way back to the computer vision training process. Then, as people use the model and correct its misses, the model will automatically improve over time. And, over time, menial tasks will be eliminated and the people will be left with the challenging tasks that are too hard for current computer vision technology to handle.
With the computer vision portion of your product arranged as a non-blocker, and with an understanding of the previous four success factors, your computer vision product is more likely to succeed. But, if you are still unsure about your product or want expert advice, then feel free to reach out to me.