Serverless technologies, such as AWS Lambda, are very handy tools for deploying code which needs to be ran infrequently. Rather than turning on a server which runs continuously, these offer on-demand computing resources. The services are designed to support lightweight tools which perform simple tasks. However, if the lightweight tools require one or two heavyweight libraries, then deploying code to these services can become problematic. But, with a little work, the problems can be worked around and switching to a more complex solution can be delayed.
I recently needed to deploy a simple machine learning script which would run weekly, so I turned to AWS Lambda. The Python script needed to pull some data from a data warehouse, perform some simple calculations, and then update the data warehouse. The script used scikit-learn, and that alone was enough to put it over the AWS size limit. To add to the trouble, it also required a data connector library which was nearly as large as scikit-learn.
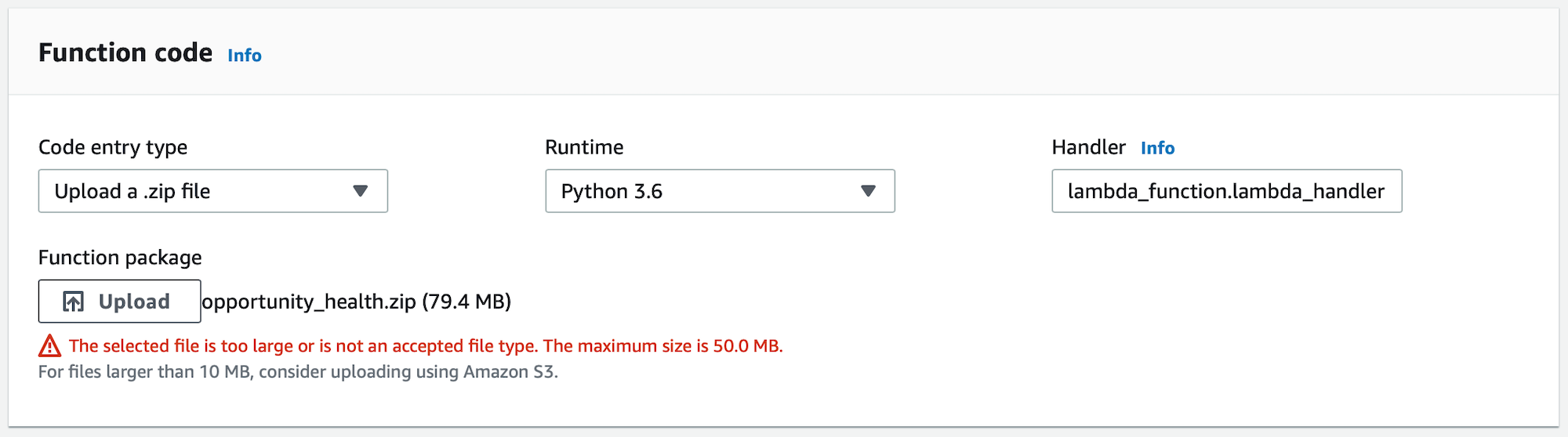
The zipped up package file was over 68MB, so it wasn’t possible to upload it using the web interface. The error tells us, “The selected file is too large or is not an accepted file type. The maximum size is 50.0MB.” No problem, the web interface gives us the option to get a file from S3, and the error message reinforces that we should do that for all packages larger than 10MB. We switch over to S3, create a bucket, and attempt to upload the package. Uploading the file to S3 via the web interface also results in an error – “100% Failed.”

Fortunately, that problem can be worked around by using the AWS command line tools.
aws s3 cp big_lambda.zip s3://big-lambda-packages/big_lambda.zip
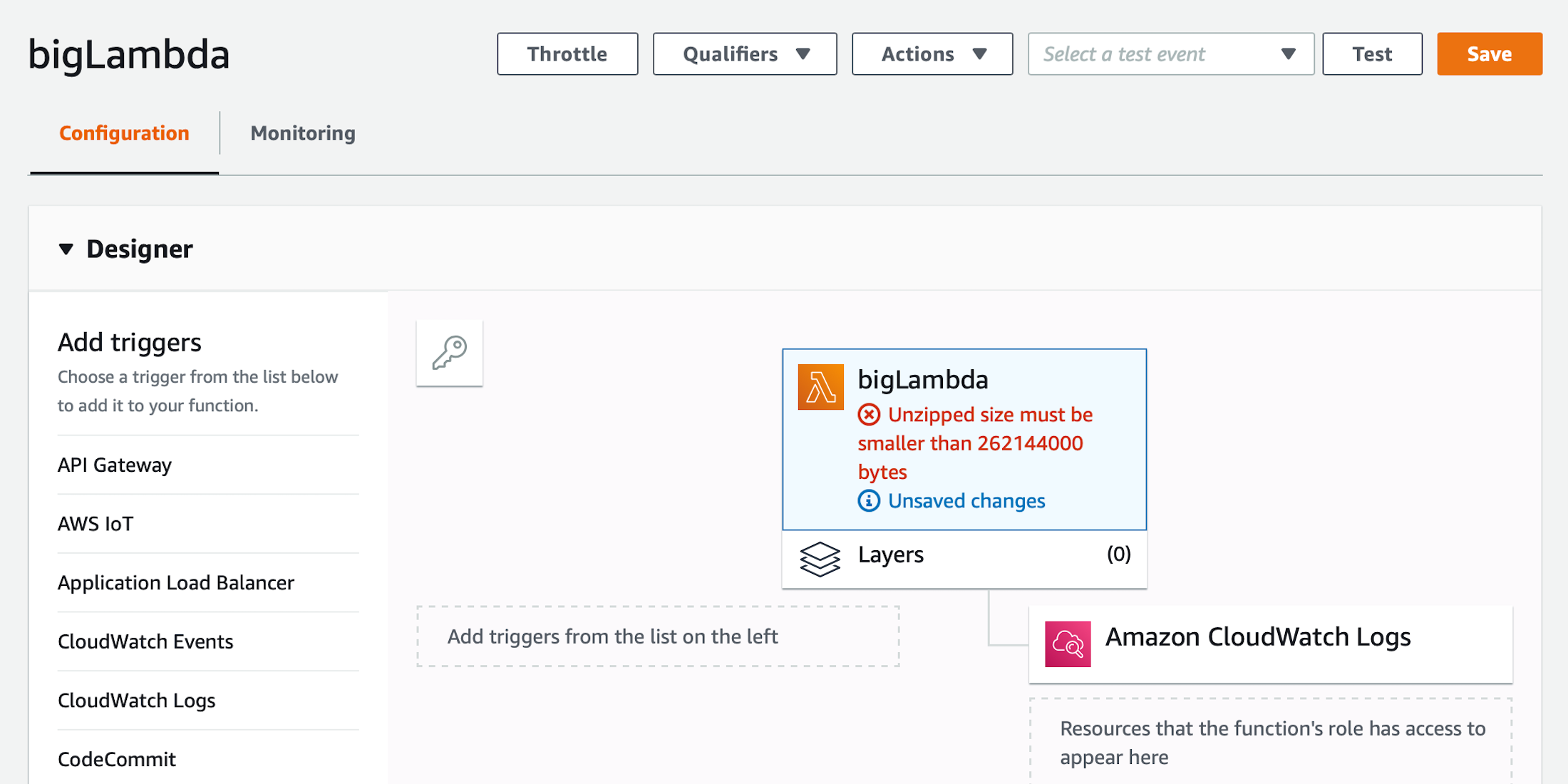
Despite working around the zipped file size problem, we quickly find that there is also a maximum uncompressed size as well. The error messages tells us, “Unzipped size must be smaller than 262144000 bytes.”
Ok, what if we remove scikit-learn from the package. We will still need the dependencies, but perhaps we can create a new base layer which contains the required libraries. I created a layer which contained the python machine learning libraries. Then I removed them from the package, re-compressed it, and uploaded it to S3. The result was the same. The uncompressed size of all layers cannot be more than the 262MB maximum which we ran in to earlier.
I nearly gave up at this point. As a last ditch effort I decided to see if a deployment tool could help me overcome the problems I was encountering. I tried the Serverless Framework. I got everything set up by using the following commands.
npm install -g serverless
serverless create --template aws-python3 --name big-lambda --path big_lambda
cd big_lambda && \
virtualenv venv --python=python3 && \
source venv/bin/activate && \
pip install -r ../requirements.txt && \
pip freeze > requirements.txt
cd ..
cp big_lambda.py ./big_lambda/
cd big_lambda && \
npm init && \
npm install --save serverless-python-requirements
I had to change the default serverless configuration file. First, I added slim:true, but for some reason that made my zipped package larger. The uncompressed package was still larger than the maximum. Next, I found the zip option. It seems that adding zip:true causes the Python dependencies to be zipped inside of the package. So, even when the package is uncompressed, the dependencies are still compressed. Now, given the serverless.yml shown below, running the serverless deploy command in the big_lambda directory was finally successful!
service: big-lambda
provider:
name: aws
runtime: python3.6
functions:
hello:
handler: big_lambda.lambda_handler
environment:
DATABASE_USER: change-me
DATABASE_PASSWORD: change-me
plugins:
- serverless-python-requirements
package:
exclude:
- node_modules/**
- venv/**
custom:
pythonRequirements:
dockerizePip: non-linux
zip: true
slim: true
There is still a problem however. If the lambda is tested it will still not run properly, it is missing its dependencies. They are still compressed. The Python script must be modified to contain the following snippet. It should be near the very top of the file, right before the import statements. This will uncompress the requirements after the Lambda instance is running and there is more disk space available.
try:
import unzip_requirements
except ImportError:
pass
With that, we have likely pushed AWS Lambda to its limits. If you attempt all of these steps and still cannot run your package, then it is probably time to move on to a more robust solution.


