Before I started making mead I was brewing beer. I wasn’t very good at it, but I would have been much worse were it not for a handful of books pointing me in the right direction. I learned the basics of brewing by practicing what I read in Charlie Papazian’s book The Complete Joy of Homebrewing. I think it was actually Radical Brewing by Randy Mosher which gave me the idea to try mead making. When I decided to give it a shot, I picked up a copy of The Complete Meadmaker by Ken Schramm. Later I incorporated ideas from Steve Piatz’s book The Complete Guide to Making Mead. Most of what I know about making mead comes from these authors.
Through a long process of reading those books and experimenting I have become an outright decent mead maker. Along the way I have developed my own style. I like to experiment with honey varietals, adjuncts, and extraction techniques, so I normally make small one gallon batches. Also, I don’t have a temperature controlled fermentation chamber, so I only make mead during cooler months. Since I only ferment four or five months out of the year I end up having numerous small batches all fermenting at once, and I like to keep the ongoing maintenance to a minimum. These factors have shaped the process which I follow. So, in the spirit of sharing knowledge to help others produce better mead, I am sharing my process.

The Appalachian Trail is sometimes referred to as the green tunnel. The truth is that many of the backpacking trails on the East Coast run under the cover of deciduous forests and have few scenic overlooks. One backpacking area within driving distance of Northeastern Ohio which breaks out of the green tunnel is the Dolly Sods Wilderness. Dolly Sods has a rough, barren appearance which is partially the result of its unique ecology and partially the result of a long history of exploitation and abuse by European settlers.
Prior to civilization creeping up to it’s borders, Dolly Sods was an inaccessible region covered with spruce, hemlock, and mountain laurel. The expansion of the railroads brought the lumber industry into the area. As the lumber industry clear cut the forests they left behind a landscape barren of trees yet fertile for fires. Fires destroyed vegetation which survived the lumber companies. By the late 1920s little of value was left and the companies moved on. The Civilian Conservation Corps started planting spruce in the 1930s, but in 1940s the US Army rolled in. They were preparing for war in Europe and needed a place to practice destroying things with artillery shells.
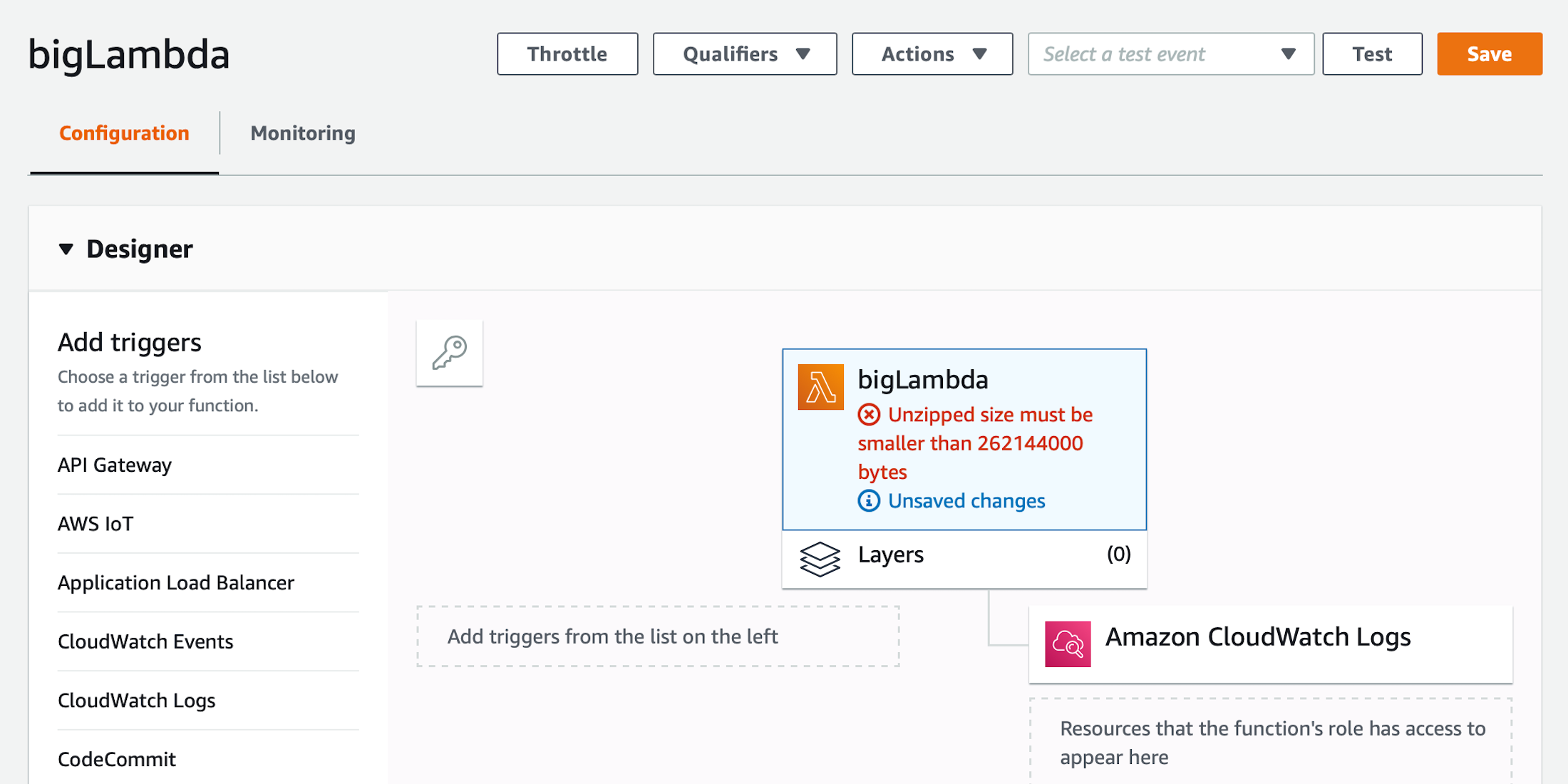
Serverless technologies, such as AWS Lambda, are very handy tools for deploying code which needs to be ran infrequently. Rather than turning on a server which runs continuously, these offer on-demand computing resources. The services are designed to support lightweight tools which perform simple tasks. However, if the lightweight tools require one or two heavyweight libraries, then deploying code to these services can become problematic. But, with a little work, the problems can be worked around and switching to a more complex solution can be delayed.
I recently needed to deploy a simple machine learning script which would run weekly, so I turned to AWS Lambda. The Python script needed to pull some data from a data warehouse, perform some simple calculations, and then update the data warehouse. The script used scikit-learn, and that alone was enough to put it over the AWS size limit. To add to the trouble, it also required a data connector library which was nearly as large as scikit-learn.

Despite having done it for a few years, I’m not a very good climber. Unlike most people, I, for some odd reason, started by climbing outdoors. I learned to set up top-rope anchors and climb the short walls of Whipp’s Ledges. My friends are much better climbers than I am, probably because they are more dedicated to practicing in the gym than I am. However, I may have a slight advantage when it comes to building anchors and rappelling. So when Doug suggested that we plan an outdoor climbing trip to Seneca Rocks where we would get to do some easy trad routes, I was super excited to go.
I might have become slightly less excited after Doug began explaining the challenges associated with these routes. From a technical perspective the routes are very easy. From a mental perspective they can be a little more challenging, at least for a beginner. We would take routes which would leave us quite exposed, and rappels would be long enough to require using two ropes. I’ve lead sport routes of around 80 feet; here we would be looking down 160 to 220 feet. It would definitely be outside of my comfort zone, which is a good place to go sometimes.

I come from a large extended family, and Easter was one of the days we all got together. My grandmother was a very kind and understanding person, so all of the various personalities that make up a large family were welcome in her home. After my grandmother passed, attendance at family gatherings began to wane. I live two hours away from my extended family and was one of the last regular attendees to family gatherings. Since we live so far away, spending time with family was the only thing we did these holidays. So, when that tradition came to an end we needed to find a new tradition that brings our family together.
Perhaps we could make a tradition of connecting with family by getting away and enjoying nature. Last year we decided to go backpacking at Archer’s Fork over Easter. It snowed. So, this year we looked for some alternative to tent backpacking. We found Oil Creek State Park, which has the 12 mile Gerard Hiking Trai and offers camping in adirondack style shelters.

Like most years, my boys and I went on a backpacking trip over spring break. This year we were either going to the Spruce Knob area or to Dolly Sods. Both of these places offer alpine-like highlands that we are not used to seeing in Ohio. Weather would determine the location. The weather at Dolly Sods was forecast to be slightly colder with a slightly higher chance or rain, so they decided to go to Spruce Knob.
We were originally going to leave Akron on Wednesday after work, but we couldn’t make it work. It’s just as well, the drive to Spruce Knob is about five and a half hours. And, the last portion follows a winding, guardrail-less one and a half lane road up the side of the mountain. So not arriving after dark was probably for the best.
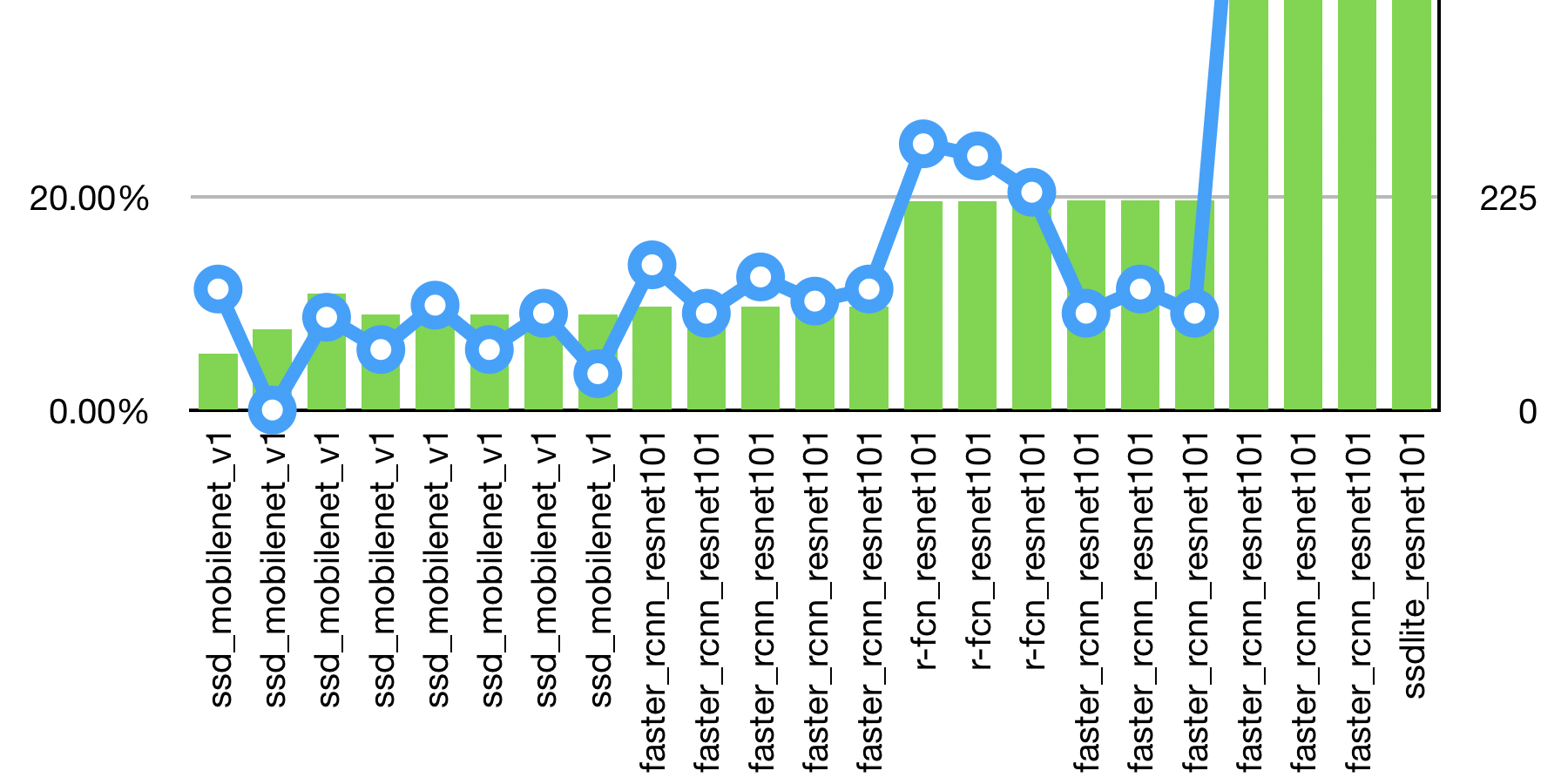
I just wrapped up a challenging computer vision project and have been thinking about lessons learned. Before we started the project I looked for information about what was possible with the latest technology. I wanted to know what sort of accuracy (precision and recall) I could expect under various conditions. I understand that every application is different, but I wanted at least a rough idea. I didn’t find the type of details that we needed, so we approached the problem in a way that would give us flexibility to change our approach with minimal rework. We used the Tensorflow Object Detection API as the main tool for creating an object detection model. I wanted to share, in general terms, some of the things which we discovered. My goal is to give someone else who is approaching a computer vision problem some information which may help guide their choices.
The customer’s objective was to get an inventory of widgets sitting on a rack of shelves. The widgets were fairly large and valuable, but for various reasons RFID and other radio based solutions were not an option. So, that is where computer vision came in. Using computer vision to solve this problem was not going to be an easy task. There were many obstacles to overcome, and I will discuss them in turn.

I previously wrote about setting up Tensorflow for object detection on macOS. After getting everything set up on the Mac I very quickly decided that it would be worth it to get Tensorflow running on something other than my main development computer. Running Tensorflow to train computer visions models on my Mac consumed all available computing resources. Nothing else could be done while the training was in progress. And, it was not taking advantage of the GPU. Using a dedicated Ubuntu machine with a GeForce GTX 1060 graphics card would be a much better option.
It took a lot of work to get a GPU enable version of Tensorflow installed and running properly. Then, after it was working for a few months, a kernel update caused it to suddenly stop working. I didn’t immediately know that the problems were caused by a kernel update, I though some other updated dependency was the culprit, so I didn’t just roll the kernel back and call it a day. Again I had to spend a good amount of time piecing together different references in order to get everything working properly. I documented everything in one place to make the process easier in the future.
The real moral of the story is probably that it is worth it to use cloud-based compute resources for these sort of tasks. That is especially true if the task allows for TPUs to be used. Regardless, if you have an unused gaming or mining machine sitting around and want to get Tensorflow running on it, this is how I did it.